Improve Service Silos with LinkedData
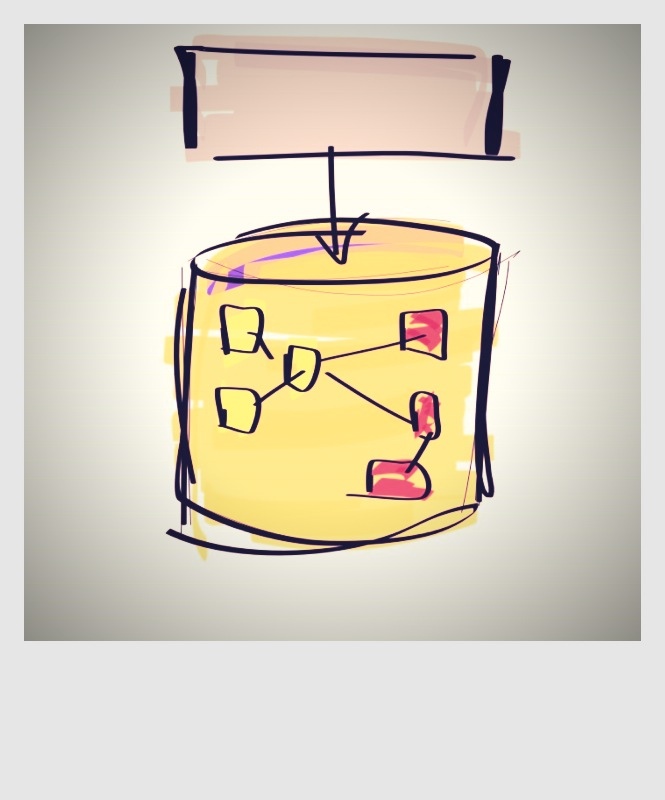
Not too long ago enterprise applications looked like this. All data stored in a single database. Data integrity was no issue, database links between all tables made sure of that. You could easily link between tables in different domains. For example, orders would link to products and customers. Unfortunately, most companies didn’t have a single database, but multiple, and a lot of duplicate data was stored in these databases.
Service Oriented Architecture
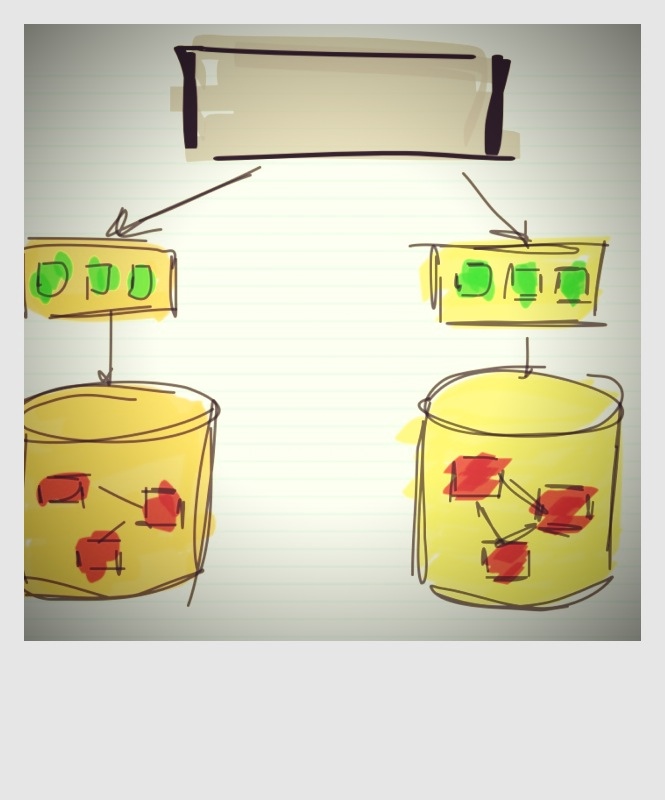
The solution: create reusable services to be used by all software in your entire organization. One customer service would for example contain all the customer data, and all the other software in you organization would have to use this service to get and store customer information.
The downside of this approach is that you loose all foreign keys between data in different domains (services). I’ve seen many surprised faces when told that all foreign keys between domains had to be removed when moving from a single database to a Service Oriented Architecture.
Using services you loose the links between data in different domains, but the situation is even worse. Even within one domain, the data exposed by a service doesn’t contain link information. It might contain keys of other data in the some domain or in another domain, but the knowledge to use these keys is hardcoded in the client which calls the service. If you retrieve some order data which contains a key to the customer, how do you know where and how to get the customer. The order data contains no clues.
So, is there a way to get back some of the advantages of foreign keys?
LinkedData
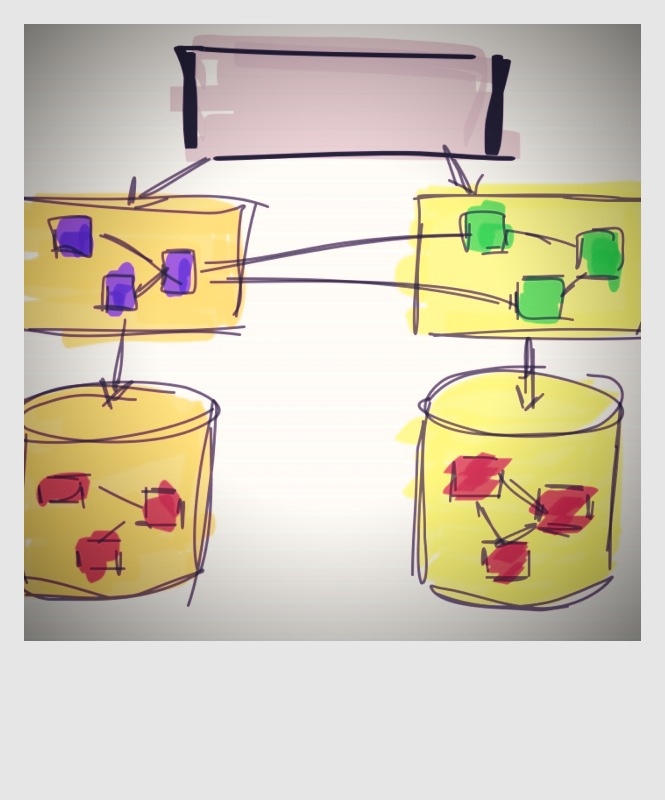
There’s no reason why data exposed by services couldn’t contain links to other data. URLs enable you to do this. REST and LinkedData both heavily rely on urls to expose related information. By interlinking all data you get an information graph. You can basically create one single information graph for your entire enterprise, just like you once had one ER-model for your entire enterprise. URL’s have an added bonus that you can also create links to external data.
This approach has some advantages. Using LinkedData you make it easier to get related information, without having to know upfront how to get the data. You don’t have to know that a customer service exists where you can get customer info by calling the getCustomerById operation. You just follow the link.
Another advantage is findability. Many companies want an internal search engine, google in abox. In a linked data situation, enterprise search solution can just traverse all links to index all your enterprise data, just like google can index all internet pages by following links.
Officially LinkedData also adds semantics or meaning to your data, but just by adding URLs you will gain a lot.
Exposing your data as LinkedData provides a lot better services foundation for building applications on than Service Silos. If you’re considering exposing your data using services you should seriously consider using URLs to expose the relationships between your data.